


Статьи / Обучение
Почему в 2026 году ультра-длинные промпты больше не нужны

Помнишь 2023–2024 годы? В Midjourney и ранних Stable Diffusion люди писали промпты по 200–500 слов: «masterpiece, best quality, ultra detailed, 8k, photorealistic, sharp focus, intricate details, cinematic lighting, volumetric god rays, rim light, highly detailed skin pores, dramatic atmosphere, award-winning, --ar 16:9 --stylize 750 --v 6 --q 2» + ещё негативный промпт на полстраницы. Это была целая наука — и она работала.
Но в 2026-м всё изменилось. Новые модели (Flux.1/Flux 2, Kling 3, Nano Banana, Grok Imagine, Veo 3, Imagen 4 и другие) радикально лучше понимают естественный язык. Эпоха «промпт-инженерии как спама ключевыми словами» уходит в прошлое. Короткие, человеческие описания часто побеждают монстров на 300+ слов.
Но в 2026-м всё изменилось. Новые модели (Flux.1/Flux 2, Kling 3, Nano Banana, Grok Imagine, Veo 3, Imagen 4 и другие) радикально лучше понимают естественный язык. Эпоха «промпт-инженерии как спама ключевыми словами» уходит в прошлое. Короткие, человеческие описания часто побеждают монстров на 300+ слов.
1. Современные модели понимают контекст и нарратив, а не просто «стек тегов»
Раньше модели обучались в основном на тегированных датасетах (Danbooru, LAION и т.п.) → они лучше реагировали на кучу релевантных слов, чем на связный текст.
Сегодня архитектуры типа FLUX, Aurora, Kling и Veo дообучены на огромных объёмах нарративных данных: описания сцен из фильмов, книг, сценариев, постов в соцсетях. Они читают предложения, как режиссёр читает сценарий.
Примеры, которые сейчас работают лучше:
Сегодня архитектуры типа FLUX, Aurora, Kling и Veo дообучены на огромных объёмах нарративных данных: описания сцен из фильмов, книг, сценариев, постов в соцсетях. Они читают предложения, как режиссёр читает сценарий.
Примеры, которые сейчас работают лучше:
- «Одинокий хакер в неоновой аллее под дождём, киберпанк, ночной Токио» → модель сама добавляет отражения, атмосферу, кинематографичность.
- Старый подход: «cyberpunk alley night rain neon reflections puddles hacker trenchcoat ultra realistic 8k detailed cinematic volumetric god rays rim lighting sharp focus intricate --ar 3:2 --stylize 800» → часто выходит «перегружено», с конфликтами стилей и случайными артефактами.

2. Перегруженный промпт путает модель — она «выбирает», что важнее, и ошибается
Когда инструкций слишком много, внимание распределяется неравномерно:
В 2026-м пользователи Flux, Kling и Grok Imagine отмечают: чем чище и короче промпт — тем меньше случайных искажений и тем точнее эмоция/динамика.
- Ключевые детали тонут среди 30 прилагательных качества («masterpiece ultra detailed best quality» и т.д.).
- Конфликты: «photorealistic» + «anime style vibrant colors» → средне-скучный компромисс.
- Модель скатывается в безопасный «аверадж» вместо точного попадания.
В 2026-м пользователи Flux, Kling и Grok Imagine отмечают: чем чище и короче промпт — тем меньше случайных искажений и тем точнее эмоция/динамика.
3. Итерации стали мгновенными — лучше уточнять постепенно
Генерация теперь занимает секунды (особенно в Grok, Kling Turbo, Flux Schnell). Получаешь 4–8 вариантов → выбираешь → пишешь 1–2 слова уточнения: «мрачнее», «ближе камера», «добавь дождь», «персонаж грустит».
Это эффективнее, чем пытаться втиснуть всё в один «идеальный» промпт с первого раза.
Это эффективнее, чем пытаться втиснуть всё в один «идеальный» промпт с первого раза.
4. Когда всё-таки стоит писать чуть подробнее (но не в стиле «старой школы»)
Коротко — не значит «одно слово». Лучшие результаты дают 15–60 слов, где акцент на:
Но даже здесь — без «8k ultra masterpiece award-winning hyperdetailed» — это теперь почти шум, который модель игнорирует или ухудшает.
- Действие / эмоции: «девушка улыбается сквозь слёзы, смотрит в камеру»
- Камера: «вид снизу, драматический ракурс», «медленный зум внутрь»
- Атмосфера: «меланхоличная», «эпическая», «уютная»
- Для видео: «громкий дождь, далёкий гром, тихая скрипка на фоне»
Но даже здесь — без «8k ultra masterpiece award-winning hyperdetailed» — это теперь почти шум, который модель игнорирует или ухудшает.
Быстрая шпаргалка по промптам в 2026 году
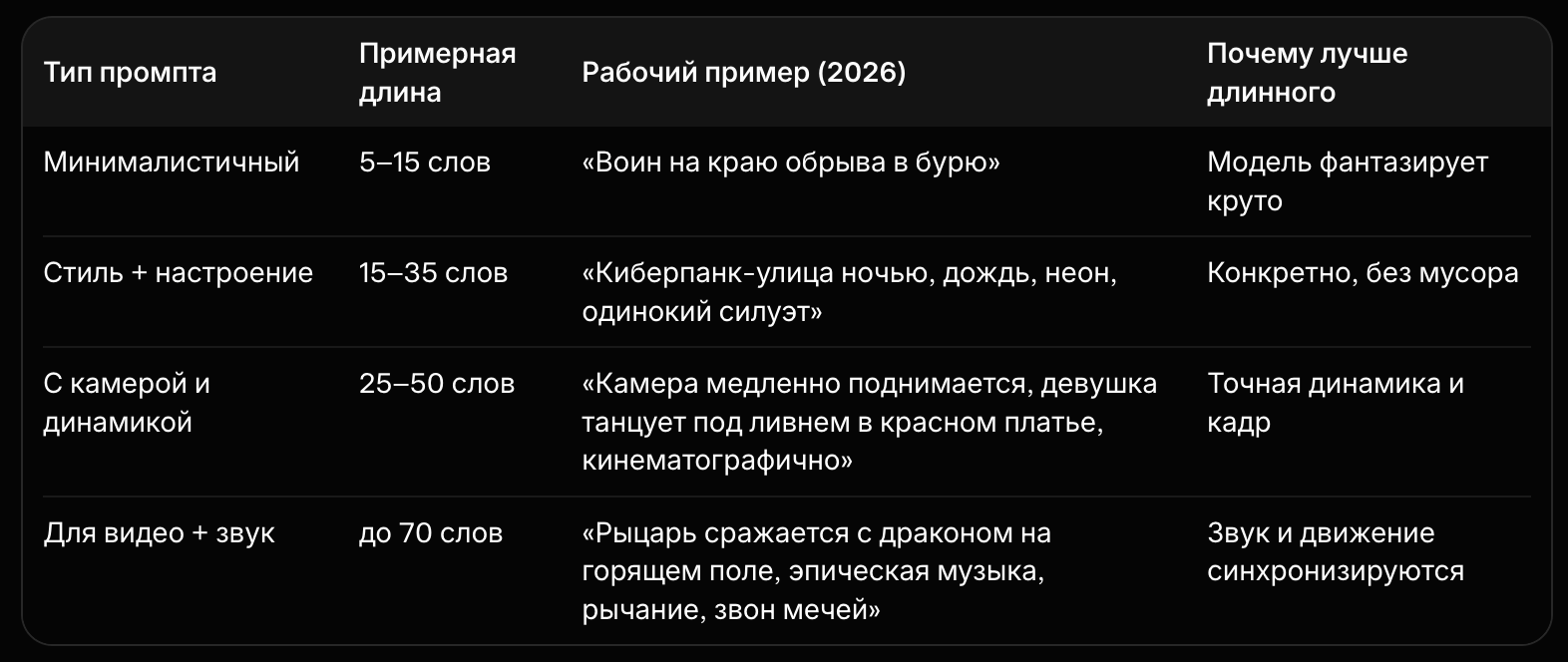
Короче: забудь про «веса», «--stylize 1000» и тонны прилагательных качества. Пиши, как будто рассказываешь идею режиссёру или другу. Современные модели сами додумают детали — и часто делают это вкуснее и чище, чем если ты пытаешься всё зажать в один промпт.